As part of our data structures sprint, we implemented a bunch of data structures, most of which had a good amount of resources out there adequately explaining how they worked.
One thing I had a bit of trouble finding good explanations for was a breadth-first tree traversal using a queue as a helper, so after finally figuring it out, I thought I'd try to lay out how it works.
So let's start out with a tree data structure:
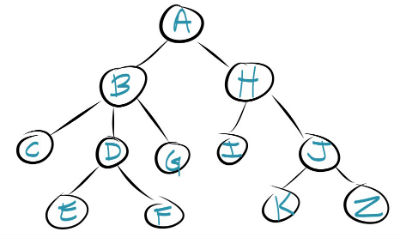
A lot of times you'll need an algorithm for traversing every object in the tree and doing something to it (logging it somewhere, calling a function on it, seeing if it matches some search criteria, etc.). One of the most popular ways of doing it is a depth-first traversal, which pretty much goes as far down a given branch as possible before checking out the next one.
There are times when you might want to go in a different order, like if you had a family tree, or a company org chart. Then you'd want to go in order of rank, or generation. So all the grandparents first, then all the next generation, then all the grandchildren. In this case, a breadth-first search comes in handy - basically going across an entire level before dropping down to the next one.
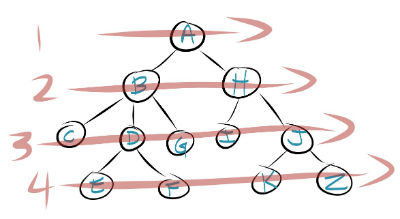
So one particularly clever way to make it work is by using a queue as basically a to-do list. A queue is a first-in/first-out (FIFO) data type which works pretty much exactly like a real-life line at a supermarket checkout or something. You put elements into the queue, and when it's time to pull one out, the one that's been in there the longest gets pulled out first.
So you set up an empty queue alongside the tree.
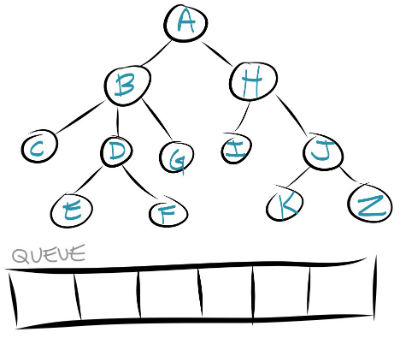
To help keep track of what we looked at, I'll use an array to keep our results. Every time we officially traverse a node (run a callback on it, examine it for our search, etc.), we put it in the array. This way we can see at the end, what order we hit the nodes in.

You start at the top of the tree, and add the first node to the queue.
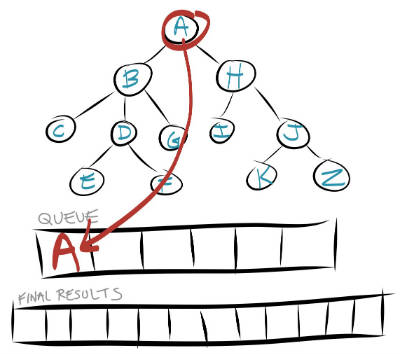
Then repeat these steps until the queue is empty:
- Take the first node out of the queue and perform your function on it (run a callback, store it in a results array, compare it to your search item).
- Add all of that node's children to the temporary queue.
Let's repeat the first few cycles of this. So step 1 says to take the first node out of the queue. The first (and only) node in the queue is currently A, so we take that out and store it in our final results list.
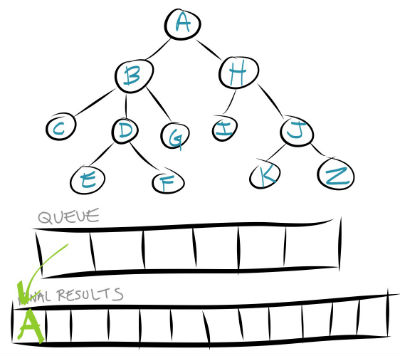
Step 2 says to add all of that node's children to the queue. A's children are B and H, so let's add them to the queue.
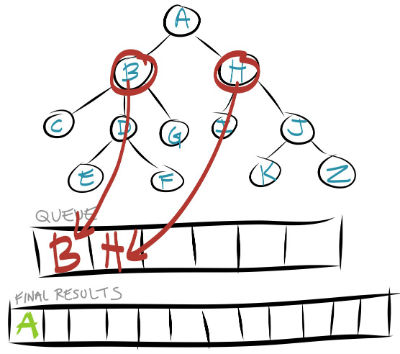
The queue is not empty, so we repeat steps 1 and 2. The first node in the queue is now B, so we remove B and store it in our final results list.
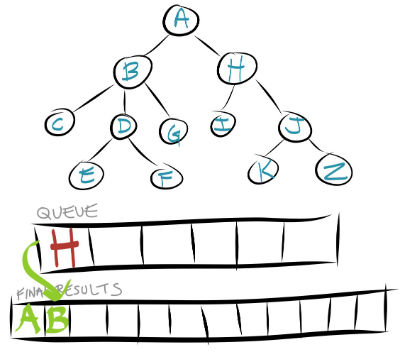
And step 2 says we put all of B's children in the queue.
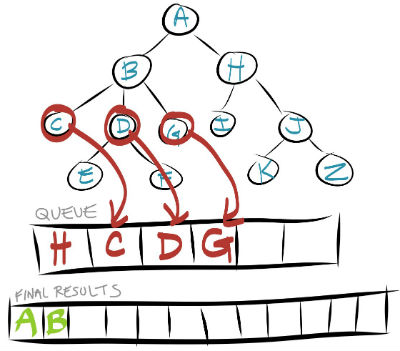
The queue is clearly still not empty, so we repeat these steps again. We (1) take H out of the queue and store it in our final results, then (2) put H's children in the queue.
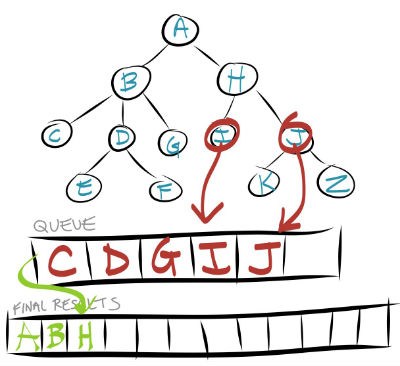
You can probably continue the pattern from here. The queue method is pretty clever because as you pass through nodes with children, you can basically save the child nodes to deal with later (so you don't lose their references after you're through with their parent) but prioritize them after the current-level nodes (so they don't get looked at before any node on the current level).
It's not the only way to do it, but I thought it was a pretty neat trick (some of the other ways are kind of straightforward).